Using AI to upgrade Enterprise Search
Documentalist is a new kind of Enterprise Search solution that enables Generative AI use cases grounded into corporate knowledge. It uses AI to (1) provide more accurate answers, and (2) handle information processing tasks.



Since the advent of ChatGPT, the vision of a chatbot capable of addressing any question related to internal knowledge has captivated companies worldwide. However, this aspiration faces significant hurdles due to inherent limitations of chat-based assistants: they can only work with a handful of document passages at a time, easily hallucinate details, and cannot meet the demands of high-privacy environments.
Looking closer, what companies really need is a new kind of enterprise search solution: one that not only retrieves the right information, but can also execute meaningful work by processing the retrieved information – just like an intern would do.
We are working on this vision, leveraging many of the recent advances in GenAI. Here's how.
Better retrieval: bridge the gap with web search
Enterprise Search solutions have historically lagged behind Web Search in effectiveness, and often fail to retrieve high-value unformation, even within the best productivity tools around (Dropbox, Google Drive, OneDrive, etc).
However, advancements in AI — and more recently in GenAI — can help bridge the gap.
Websites want to be found, documents don't.
On the web, every site employs SEO strategies to ensure it is discoverable and deemed authoritative by search engines. All web pages use the same structured format — HTML — making the components of the page obvious (title, level of headings, metadata, …). Web pages are also interconnected through hyperlinks, enabling the identification of authoritative sites with the following core idea: “A website is important if other important websites are connected to it”. This recursive approach to determining a site's importance, famously known as PageRank1, leverages the web's interconnected nature.
Files, on the other hand, are isolated (not interlinked), disorganised, and for the vast majority have no structured format. They don't care about being found. Nobody is doing their “SEO” to enhance their discoverability.
Use AI to do “the SEO of documents” to make them discoverable
Advances in AI can help your documents discoverability, as if full-time employees were doing “SEO” on them. It can be framed as a two steps process:
- Document understanding: AI enables to process any file type, and extract more information from the file content.
- Linking documents together: GenAI can be leveraged to detect implicit references, either as entities mentionned in both documents — think NER here, like organisations, people, places — or as semantic proximity that can result of comparing each document against every other one4.
These are two avenues of research that we are exploring at Dotprod AI, to dramatically improve the discoverability of corporate documents.
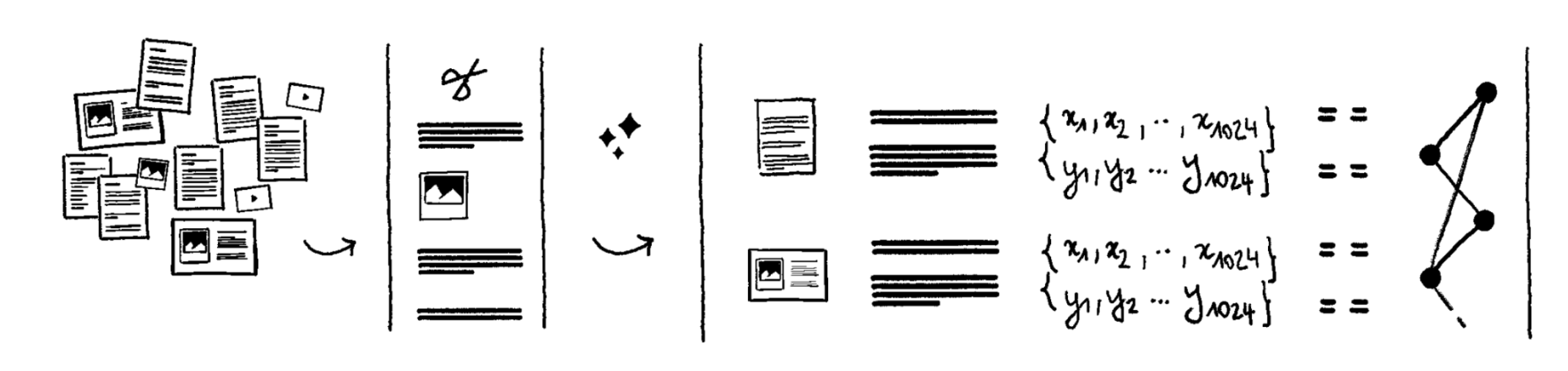
Use AI to understand queries and retrieve relevant information
The typical search box in productivity tools only supports keyword search from documents titles, and sometimes from the content in the files, with great limitations for PDFs, scans and images.
Experience proves keywords are not enough to effectively search within millions of corporate documents. People often don't remember the exact keywords, or need to find related information (not only exact matches). This is why we experimented with advanced AI retrieval methods (see below) giving users more flexibility in expressing what they are looking for in natural language.
With these techniques we can retrieve much more relevant documents aligned with the user query. We then needs to decide how to order them.
Use AI to simulate queries to optimise search algorithms
Public search engines benefit from billions of queries to optimise their ranking of documents. Every click on a Google search result is a signal that this site was the most relevant to the query, adding this (query, site) pair to a dataset later used to improve ranking algorithms.
Enterprise Search companies don't have such datasets, as they don't have the scale of public search engine, and also because they can't really collect one and guarantee privacy at the same time.
We intend to bridge the gap here with synthetic datasets generated by a range of LLMs configured with different user profiles. While indexing the documents of a company we can simulate millions of relevant (query, document) pairs, as if thousands of employees were searching documents all day long!
As demonstrated lately, textbook-quality synthetic datasets5 are much more efficient than real-word-noisy datasets to train SLMs. So, these would be perfect candidate to train our custom AI models for each customer, while still preserving the utmost level of privacy and confidentiality for their corporate data.
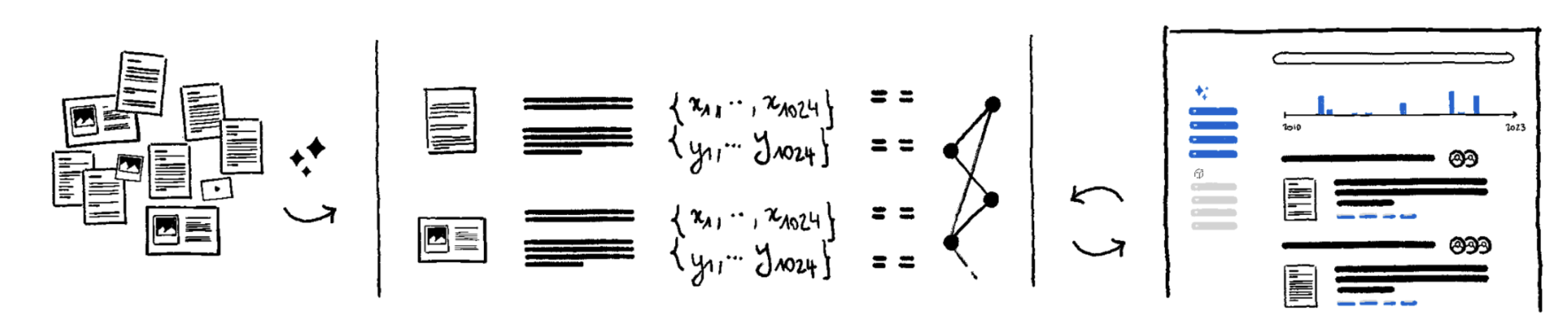
Handle information processing tasks
Beyond Search: Knowledge Work Applications
Once you can effectively retrieve relevant information from your files, you can use it as the input to different Generative-AI models to perform actions on them.
We believe that every employee will soon routinely delegate information processing tasks to AI models, as they would to an intern. It will be a bit like using Excel today, delegating heavy calculations to a machine. And it will certainly reduce the need for ad-hoc software.
This is our mid-term goal: progressively support such “knowledge work” applications and offering teams around the world a close to infinite pool of interns ready to crunch tasks for them.
- RFP: A consulting firm needs to answer a RFP and asks Documentalist to:
- read every question of the RFP,
- search for all documents containing information to answer them (or provide it with a set of identified documents to work with)
- read those documents and take notes of passages in a scratchpad6
- jump from one document to the other using fine-tuned multi-hop reasoning models7
- and finally prepare a draft of answer for each question with transparency on the thought process and sources used.
- ESG compliance: A law firm provides its customers with the list of non-financial disclosure requirements. It provides Documentalist with the customer profile, and asks it to:
- Read all the applicable legislations in a curated database of >500 documents,
- Identify all rules applying to this customer profile (depending on size, location, industry, etc)
- Take notes in a document with links to source paragraphs.
- Information extraction: A fiscal consulting firm with 20 years of experience has millions of files in a shared drive, with mostly PDF or scans of letters exchanged with the administration containing answers to sensitive and complex questions. All this information is highly valuable, but not searchable. With Documentalist, this customer can ask:
- Did we already come across this question (or similar). How did we answer?
- Call quality: An insurance company wants to score customer calls against their compliance and quality guidelines, to automatically identify which calls might require double-verification. They can ask Documentalist to
- transcript recorded calls,
- read the transcript to apply a custom scoring system8
- build a spreadsheet listing all calls and their scores.
- &hellip:; and many more possibilities.
If you read this far and are interested, let's chat about your use case! We are looking for design partners to work on high-value use cases.
Let's chat!Footnotes
- PageRank is a link analysis algorithm developed by Google founders Larry Page and Sergey Brin, which helps in ranking web pages in their search engine results. ↩
- Large Language Models can be very sensitive to prompt formatting as shown in Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting. On the other side, it's important to note that this sensitivity has been the source of creative use and performance optimization also known as prompt engineering. ↩
- Initially developed by OpenAI, CLIP learns visual concepts from natural language descriptions, effectively bridging the gap between text and images through a single, unified representation space. It is designed to understand and generate a wide array of visual tasks without needing task-specific training data, making it highly versatile and powerful for various applications. ↩
- Comparing each document against every other one implies a time-complexity of , which will be addressed in an upcoming article ↩
- Started the familly of Phi models with Textbook Are All You Need, Bubeck et al. 2023 ↩
- Inspired by Scratchpad for Intermediate Computation, Nye et al., 2021 ↩
- Inspired by Robust Multi-hop Reasoning, Khattab, 2021 ↩
- Inspired by the idea behind LLM-as-a-Judge, L Zheng, 2023 ↩